안녕하세요.
오늘은 자주 사용되는 String과 StringBuilder, StringBuffer에 대해서 포스팅해보겠습니다.
# 공간적 차이
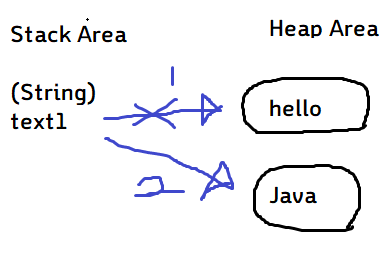
- String
String은 값 변경 시, Heap영역에 공간이 새로 생성됩니다. 추후에 GC에 의해 제거됩니다.
- StringBuilder, StringBuffer
이 둘은 값 변경 시, Stack공간에 값을 저장해 값만 바꿔씁니다.
-> 따라서 값이 자주 변경된다면 String보다는 StringBuilder, StringBuffer 사용을 권장합니다.
# 시간적 차이
글보단 시간측정을 해보겠습니다.
public static void main(String[] args) throws Exception{
// 1. StringBuilder 시간 측정
long time1 = System.currentTimeMillis();
StringBuilder builder = new StringBuilder();
for(int i=0;i<100000000;i++) {
builder.append("a");
}
long time2= System.currentTimeMillis();
System.out.println("StringBuilder ::: " + (time2 - time1));
// 2. StringBuffer 시간 측정
long time3 = System.currentTimeMillis();
StringBuffer buffer = new StringBuffer();
for(int i=0;i<100000000;i++) {
buffer.append("a");
}
long time4= System.currentTimeMillis();
System.out.println("StringBuffer ::: " + (time4 - time3));
// 3. String 시간 측정
long time5 = System.currentTimeMillis();
String str = "";
for(int i=0;i<500000;i++) {
str += "a";
}
long time6= System.currentTimeMillis();
System.out.println("String ::: " + (time6 - time5));
}StringBuilder와 StringBuffer는 각각 1억건의 연산을 했을 때,
String은 Heap사이즈가 초과해서? 오래걸려서? 그런지 1억건으로 하니 측정이 안되서 50만건 연산했을 때
각각의 속도를 측정해보았습니다.
- 결과

결과가 보이시나요? 비교적 적은 50만건만 연산한 String의 속도가 현저히 느린 것을 확인할 수 있었습니다.
1억건씩 연산한 StringBuilder와 StringBuffer는 StringBuilder가 현저히 빠른 것을 볼 수 있었습니다.
"? 그러면 StringBuffer는 언제쓰는거지?" 라는 의구심이 들어 찾아보았습니다.
StringBuffer는 StringBuilder와 다르게 동기화를 지원하여, 멀티 쓰레드 환경에서 안정성을 가지고 있습니다.
- 결론
문자열 단순 조회 용도 = String
연산이 (추가,삭제 등 ) 자주 일어날 때에, 단일 쓰레드 환경 -> StringBuilder
연산이 (추가,삭제 등 ) 자주 일어날 때에, 멀티 쓰레드 환경 -> StringBuffer
자주 사용되는 문자열을 저장하는 객체들에 대해서 알아보았습니다.
보통은 단일 쓰레드환경에서 자주 사용하니 StringBuilder를 잘 기억해놓아야겠네요!
감사합니다.
'Java' 카테고리의 다른 글
| [Java] 추상 클래스 vs 인터페이스 (0) | 2021.09.03 |
|---|---|
| [Java] 접근 제한자란? (0) | 2021.09.02 |
| [Java] Garbage Collector (0) | 2021.08.25 |
| [Java] JVM이란? 정의 및 동작 방식 (0) | 2021.08.22 |
| [Java] 특징 1. 객체지향 프로그래밍 (0) | 2021.08.21 |